

Edge computing is a service that processes workloads away from the original data source while minimizing network induced latency.
Edge computing has a similar consumption-based model as cloud computing. Both are available as-a-service, where the customer does not require to manage the underlying infrastructure. The difference between cloud and edge computing use cases is the tolerance for latency.
Latency can either be an enabler or prohibitor, where real-time applications require little to no latency, while large analytics jobs do not need immediate processing. Latency is incurred at the three components that are used when processing requests – compute, storage, and network.
Cloud computing services are hosted in large data centers and can offer large amounts of processing power and copious amounts of memory in a centralized location. Alongside compute, cloud also offers storage services which are highly scalable. These large amounts of compute, memory, and storage are typically hosted in single data centers, with a handful of locations available throughout the world. If a workload is hosted on the US West Coast, requests from European users would need to traverse the whole distance routrip, incurring >100 milliseconds of latency per request.
Edge compute, on the other hand, focuses on distributing CPU, memory, and storage across a larger number of geographically spread out points of presence. These points of presence have limited resources compared to cloud data centers, but are able to scale horizontally across multiple locations. The result is that requests made to edge compute services will be smaller and lighter weight compared to those made to cloud instances.
This makes edge computing suitable for a variety of latency-sensitive applications, which include:
- Website delivery – Edge computing offers the infrastructure required to build and run programmable content delivery networks that can use logic at the edge to deliver dynamic websites. These can enable logic such as custom request handling, geofencing, content-aware load balancing at layer 7, device detection and asset optimization, file compression and image resizing, asset prefetching, personalization, such as currency conversion, multilingual website delivery, and A/B testing.
- Media delivery – computing at the edge can be used to develop and run services such as video players, ad insertion, live captions and subtitles, video scrubbing and watermarking, overlays, waiting rooms, and live video recording.
- Industrial Applications – In industrial settings, edge computing can be used for real-time monitoring and analysis of control systems without large investments in local or on-premises hardware. Data generated on the factory floor is forwarded to the closest point of presence where it is analyzed for use cases such as predictive maintenance, quality control, and process optimization.
- Computer Vision – Edge computing accelerates computer vision applications by processing video streams locally, reducing bandwidth requirements and enabling real-time response. Edge nodes equipped with GPU or specialized AI accelerators can perform object detection, facial recognition, and motion analysis with latencies of 20-100ms. This architecture is essential for use cases such as surveillance systems and retail analytics, where immediate visual processing is critical for decision-making.
- Personalization – Edge computing can analyze user sessions and access and behavior patterns to generate real-time recommendations and targeted advertising, particularly useful in e-commerce scenarios.
- Cloud Gaming – Edge computing enables cloud gaming by positioning game servers and rendering capabilities within <20ms of players. Edge nodes handle game state management, input processing, and video streaming, delivering responsive gameplay with minimal latency.
Due to the underlying difference in large workloads in the cloud and smaller workloads at the edge, the underlying infrastructure architecture and execution environments are different between edge and cloud computing. We will present these in the following sections that talk about compute offerings, storage offerings, and network architecture.
Compute Offerings
Organizations that want to outsource their infrastructure to a third-party provider can choose between a range of infrastructure-as-a-service offering, which include the following:
- Colocation – provider offers space, power, and connectivity to host the customer’s physical servers. Customer is responsible for deploying and managing the physical servers.
- Bare metal – provider offers dedicated hardware for each customer, the customer being responsible for all the software components, including hypervisors and operating systems.
- Virtual machines – provider manages the physical servers and hypervisors, allowing customers to provision virtual machines from a self-serve portal
- Containers – provider manages the operating system and container engine, allowing customers to provision and manage containers.
- Severless (container-based)- provider abstracts the whole infrastructure stack, executing customer scripts upon request. This serverless service runs on top of a container-based infrastructure.
- Edge-native serverless – this service processes customer requests on-demand and is based on binary instruction formats such as WebAssembly and V8.
Cloud services providers typically focus on virtual machines, containers, and serverless services, while edge services providers can provide any of the above services if available.
All of the above examples are available using x86 architectures, but some providers have started offering GPU- and ARM-based compute instances.
Storage Offerings
While storage is a different set of services, the choice of storage types is closely related to the type of compute used and associated use cases. The two most common storage offerings are object and block storage.
- Object storage – Object storage is well-suited for large amounts of unstructured data, such as backups, archives, and multimedia files. It’s also good for data analytics, distributed data storage, and big data applications. Object storage is highly scalable and customizable, but it takes longer to process requests than block storage. Object storage is used to store and manage large volumes of unstructured data, making it well suited for big data use cases, such as artificial intelligence, machine learning, and predictive analytics.
- Block storage – Stores data in fixed-sized blocks, each with a unique identifier. Block storage is good for structured data, like databases and virtual machines, and for transactional data and small files that need to be accessed often. Block storage is fast, but it’s usually more expensive than object storage.
Network Architecture
Edge compute providers operate global networks that can optimize network traffic and distribute it to the servers that sit closest to the devices making requests.
This is in contrast to cloud service providers, which have little to no focus on the network component. They offer virtualized networking to connect services within their data centers, and offer some products such as Direct Connect and Express Routes for on-premises to cloud datacenter connections.
Latency-Based Use Cases
As previously mentioned, the main difference between cloud and edge use cases is the tolerance for latency. Below we will describe three use cases for high, medium, and low latency tolerance.
High Latency Tolerance
This architecture is designed for large-scale data analytics where processing time is less critical than cost-effectiveness and storage capacity. For example, a retail chain analyzing historical sales data to predict future inventory needs raw data ingestion into object storage, nightly batch processing for sales analysis, monthly deep learning model training, and quarterly trend analysis across multiple years.
- Cloud-based Virtual Machines: persistent compute instances which can scale as required depending on job completion time.
- Object Storage: Used for data lake implementations and hierarchical storage with hot/warm/cold tiers.
- Large network data transfers from on-premises data generation to cloud-based storage. No dependency on network latency
Medium Latency Tolerance
This architecture balances performance and cost for enterprise applications requiring regional access with moderate latency requirements. It can be used for real-time video processing of surveillance camera feeds, optimizing for consistent performance while handling high-bandwidth video streams and compute-intensive ML inference.
- Edge-based Virtual Machines or Containers using GPU-accelerated compute nodes
- Block Storage with SSD backing
- Load-balanced Anycast network with points of presence within 1000 miles of camera locations.
Low-latency Tolerance
This architecture leverages WebAssembly at the edge with key-value storage for real-time web applications requiring consistent sub-second response times, such as real-time document or code collaboration.
- Edge-based WebAssembly (WASM) Runtime
- Key-Value Storage
- Load-balanced Anycast network with points of presence within 500 miles of camera locations.
Hybrid Cloud-Edge Strategy
As both edge and cloud are infrastructure-as-a-service products with similar consumption models, they can be used together in certain scenarios, such as :
- Cloud bursting – edge computing handles the base workload while leveraging cloud resources for capacity overflow. This approach is effective for applications with variable demand, such as e-commerce platforms during sales events or gaming servers during peak hours. The edge infrastructure maintains low-latency operations for normal traffic, while automated scaling triggers spin up cloud resources when demand exceeds local capacity. This ensures cost-effective operations during normal periods while maintaining service quality during peak loads.
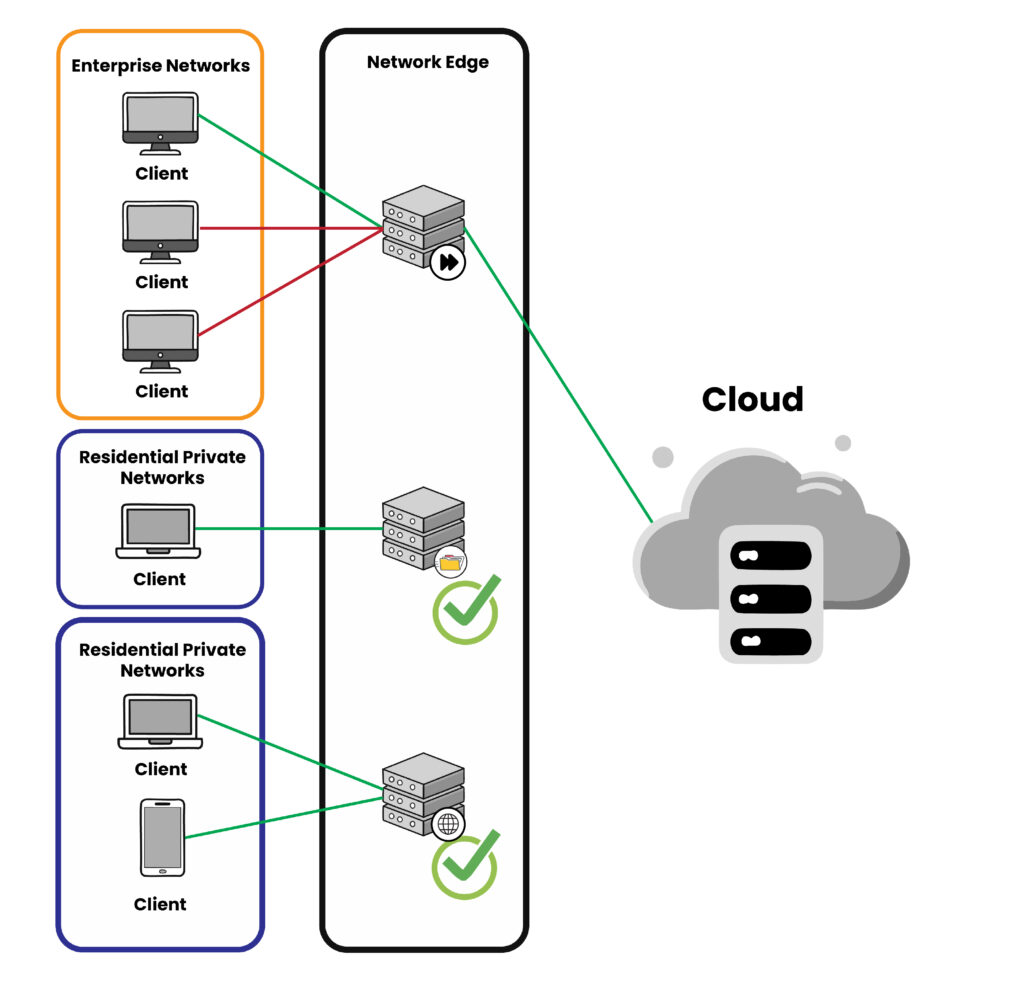
- Cloud storage integration – creates a tiered data management system that combines edge and cloud storage capabilities. Edge locations utilize high-performance block or key-value storage for hot data and recent history, while cloud object storage serves as a cost-effective repository for long-term archival, backup, and comprehensive data analytics. This pattern is particularly valuable for applications like video surveillance systems or IoT deployments, where local storage handles immediate data needs while cloud storage manages historical data and enables broader analytical capabilities.
- Large processing – Edge locations handle real-time processing needs and initial data filtering, while resource-intensive operations are routed to the cloud for processing. This pattern is ideal for complex workflows like AI/ML operations, where edge computing performs real-time inference and initial data preparation, while the cloud handles intensive model training and batch processing tasks. This approach optimizes for both performance and cost by placing workloads where they’re most efficiently processed.
NetActuate Global Edge
NetActuate Global Edge runs on top of 40 data centers across six continents interconnected by an Anycast private network. Edge compute with NetActuate is available as virtual machines, bare metal, and colocation. On top of edge compute infrastructure, NetActuate also provides value-added services such as Kubernetes, S3 compatible global object storage, load balancing, and DDoS protection.
To learn more about NetActuate’s Edge Compute solutions, schedule a call with one of our engineers.